
Written by Michael (Mike) Erlihson, Ph.D.
This review is part of a series of reviews in Machine & Deep Learning that are originally published in Hebrew, aiming to make it accessible in a plain language under the name #DeepNightLearners.
Good night friends, today we are again in our section DeepNightLearners with a review of a Deep Learning article. Today I've chosen to review the article Rethinking Attention with Performers
Reviewer Corner:
Reading recommendation From Mike: A must for transformers lovers and NLP people
Clarity of writing: High
Math and Deep Learning knowledge level: A basic knowledge of kernels, and a good understanding of transformers' self-attention
Practical applications: The suggested method can be used for every task where the transformer's self-attention squared complexity is computationally problematic.
Article Details:
Article link: available for download here
Code link: available here
Published on: 09/03/2021 on Arxiv
Presented at: ICLR 2021
Article Domains:
- Transformers with low computational complexity
Mathematical Tools, Concepts, and Marks:
- Self-Attention mechanism
- Softmax Kernels
- Positive Orthogonal Random Features
The Article in Essence:
The Transformer is a deep neural network architecture that was introduced in 2017 in the article attention is all you need. Since then, Transformers have conquered the NLP world and became almost the default architecture in the field. The majority of NLP articles in the past years are using Transformers in this way or another. Lately, Transformers have also started showing up in the visual domain and appeared in several articles.
The Transformer input is a set of items (a word, sub-word, image patch, audio sample, etc.), where each item is represented as a vector. The core of the Transformer is the self-attention (SA) mechanism, which quantifies the connectivity between different items in the set. The Transformer's goal is to produce a vectored representation of each item in the set while taking into account the dependency in other items. In NLP this is called contextualized embedding. By the way, a recently published article shows that the success of the self-attention mechanism originated in the combination with skip-connections and other fully-connected layers. Furthermore, it is important to note that when the input is in inherent order (such as text or an image), the input must include Positional encoding, a vector that encapsulates information about the item position in the series. When the input is a set, with no order importance (permutation invariant), there's no need for a Positional encoding.
Since in the first stage, the SA mechanism calculates the similarity of each item to every other item in the series, the complexity of this step is quadratic w.r.t the series length (let's mark it as L). This complexity may be cause problems when dealing with long series, in terms of the required computational and memory resources. This problem can get even worse for architectures that are composed of several Transformers layers. This issue is one of the major ones preventing Transformers from taking over the visual domain (besides that Transformer, in its classic form, can not use the local connections that occur in images, although this can be handled by using more sophisticated training methods). A large number of patches in high-resolution photos is the main reason for this: the standard SA mechanism implementation may be computationally heavy and require large memory consumption).
During the last year, several published articles suggested computationally lighter variants for the Transformer, such as Linformer and Reformer. To lower the Transformer's quadratic complexity, most of these articles made assumptions about the series items relations and/or about the Q, K matrices which are used to calculate the SA. According to this article authors, these lighter variants demonstrated low performance, compared to the original, computational heavy, Transformer version. The article argues that the reason for this low performance is a lack of the existence of the assumptions, that these light versions are based on.
The authors in Rethinking Attention with Performers don't make assumptions about the properties or structure of the input items. They offer a rigorous mathematical frame to approximate the attention matrix with a linear complexity w.r.t the input length. Additionally, the approximation parameters can be altered to reach any wished accuracy for the attention matrix. The article proves that this approximation is:
- An unbiased estimation (or very close to it) of the attention matrix
- Uniformly converged (same convergence speed for every item of the attention matrix)
- has a low variance
Basic Ideas
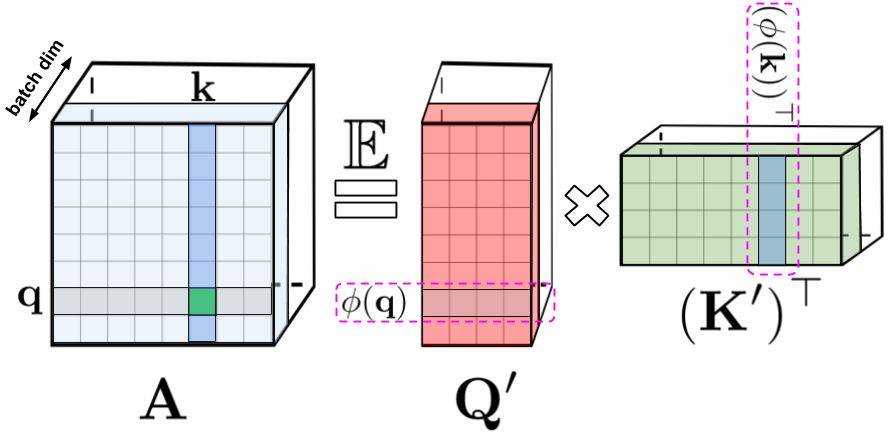
The attention is calculated using by performing Softmax on the matrix multiplication K* and Q*. K* and Q* matrices are reached by multiplying the Query and the Key matrices (marked as Q and K) on the input vectors q_i and k_j. All the internal multiplications are normalized by d1/2 but this isn't important to understand the computation principle. The Softmax action is performed on a matrix, in which its items {i, j} are an internal multiplication of the vectors q_i and k_j. The size of this matrix is LxL, where L is the size of the input. The output of the Softmax action, A, is multiplied by the matrix V* which is made of the multiplication of embedding vectors on V, the value matrix. The size of V* is Lxd, where d is the dimension of the embedding vectors. Time and memory space complexity is in order of O(L2). And this is the core issue of using Transformers on long text, such as a whole paragraph or high-resolution image patches.
For more information about the original transformers, these two blog posts are highly recommended sources.
The article suggests a method to approximate the Softmax on the matrix multiplication K* and Q* by multiplying two matrices - Q' and K' - with the dimensions of Lxr, where r is significantly smaller than L - r << L). This enables replacing the multiplication order when calculating the SA:
- The V matrix, sized
Lxd, is multiplied by the replaced K' matrix, sizedrxL, achieving a new matrix A', sizedrxd. - This A' matrix is multiplied by Q', sized
rxL.
It's easy to see that the memory and the computational complexity, in this case, don't linearly depend on L any longer.

But the main question here is how to build these matrices Q' and K', such as their multiplication is an approximation with the required properties (unbiased, low variance, uniformly converged)?
The authors suggest a method called FAVOR++ to approximate the matrix A, the output of performing Softmax on the multiplication of q and k vectors. The article offers a more general method of approximation of any function of the form K(q, k), where K is a positive kernel (a function with specific properties). The approximation is the expected value of the internal multiplication of φ(q) and φ(k), which is marked as E(q, k), where φ is a randomized function Rd ➝ R. If you are familiar with Random Fourier Features, you might see the resemblance.
The article suggests using a function of this form:

where
- fi i=1,..l are functions R ➝ R
- h is a function Rd ➝ R
- ωi i=1..., m are randomized vectors, selected (only once over the whole calculation) from the distribution D on Rd.
In most cases, this distribution D will be isotropic. That is, its distribution function is fixed on a sphere. For example, by settingh≡1,f1=cos(),f2=sin(), andDis a standard Gaussian distribution, we get an approximation of a Gaussian Kernel, Kgauss. In our case, we need to find an approximation for SM(x, y) = exp(xTy) (up to the normalization). We may notice that:
SM(x, y) = exp(||x||2/2) Kgauss(x, y) exp(||y||2/2)
It is easy to show that SM(x, y) can be approximated by a function, defined by formula (1), as so:
h(x) = exp(||x||2/2), f1=cos(), f2=sin()
So in fact, we managed to approximate the items of the matrices Q* and K* into a replacement matrix by an internal multiplication of the vectors, calculated of q_i and v_j with the phi function. Therefore, we can multiply the matrices of the attention matrix in a different order, and by this, reducing the complexity into linear w.r.t the input length.
There is, however, a small "catch" here. Softmax is a convex linear combination (in which all its parameters are positive and normalized) of the replaced multiplication Q* and K*. When we replace this calculation with the approximation, which can be any value - also negative, it may cause serious inaccuracies, especially where the Softmax values approach 0. Remember that Softmax measures the similarity between the query and the key vectors across different items, so most of these values will be close to 0. The article also demonstrates that by using an approximation epsilon (3), these inaccuracies, compared to the true values of Softmax, are quite significant.
So, not only that we need to approximate the Softmax calculation, but also we must do it with non-negative functions. The article uses this approximation:

Which is given by:

The article also shows that the Softmax approximation through this expression, given by these two equations, can successfully approximate the true values of the attention matrix in a uniform way and with low variance. To make this approximation more accurate, given the same number of randomized vectors of a Gaussian standard distribution ωi i=1..., m (only once across the whole calculation), the article performs an orthogonalization of these vectors. One way to do it is using the Gram-Schmidt process.

Finally, the article proves in a rigorous form, with quite nontrivial tools, the theoretical "good" qualities of this approximation. Most of this article - about 30 pages - is just mathematical proofs.
Achievements
The article is the first (as far as I know) to successfully decrease the Transformer's attention complexity, both for space and calculation, into linear order, w.r.t the input size, without any previous assumptions on the Key, Query and Value matrices, nor on the attention values.
P.S.
The article suggests a method to lower the Transformer's complexity to a linear order and proves all the arguments also in a rigorous form. The article is not easy to read, but luckily, to understand the main idea, one does not need to understand all the proofs - the first 5-6 pages are more than enough.
More detailed information about the performer may be found at Google.AI blog
#deepnightlearners
This post was written by Michael (Mike) Erlihson, Ph.D.
Michael works in the cybersecurity company Salt Security as a principal data scientist. Michael researches and works in the deep learning field while lecturing and making scientific material more accessible to the public audience.


