

Reviewer(s) Corner
Read Recommendation from Mike & Avraham: highly recommended for representation learning fans, especially for those interested in contrastive learning
Writing Clarity: average plus
Prerequisite (prior knowledge):
- Basic principles of representation learning and contrastive learning
- Importance sampling
Possible Practical Applications:
Can be used to obtain powerful data representations from unlabeled datasets
Paper Details
- Paper: https://arxiv.org/abs/2112.08132
- Code Link: https://github.com/ssl-codelab/uota
- Date & place of publication (last version): Arxiv, 15.12.2021
- The conference where the paper was presented: NeurIPS 2021
Paper Research Areas
- Self-supervised and representation learning
- Contrastive learning
Mathematical concepts, tools, and notations in the paper
Introduction
Augmentations serve as a standard technique for enriching a dataset - we transform (or augment) examples from our dataset in various ways to obtain more data. For instance, assuming we have a picture of a cat, then rotating, resizing, or cropping it, etc, isn’t supposed to change the fact that the picture depicts a cat. These simple operations allow us to leverage more instances of the same class by using our existing data. Since augmented examples belong to the same class as the original examples, we have not only gained more data but more tagged data as well. We can also benefit from augmentations in an unsupervised learning regime when the task is to obtain powerful data representations for various downstream tasks due to their (augmentations) ability to "bias" the model towards important semantic features.
This use of augmentations is based on a simple and reasonable assumption, but as we will see, this assumption does not always hold. Under this assumption, examples are invariant to augmentations, meaning that reasonable changes to the example would not alter the class it belongs to, and the semantic contents of the data would be preserved. This paper upends this assumption and shows that it can be problematic since some augmentations may change the semantic content of an example. The authors show that non-cautious usage of augmentations can hurt data representation quality produced by the model. The authors also propose an elegant solution to alleviate this issue for representation learning tasks.
Remark: Representation learning is the task of training models to produce data representations (features) on unlabeled datasets.
Approach
Problem and motivation
The authors attempt to address the existence of “false” positive pairs of examples, which might occur during representation learning, for example, while training models with contrastive learning methods. In a contrastive learning setting, positive pairs are usually built by applying "semantic content preserving" augmentations on a given example.
Recall that the primary assumption made by contrastive methods is that semantically similar examples (positive pairs) should lie close together in latent (representation) space, while dissimilar examples should lie farther apart in latent space. In the visual domain (images), a pair of similar examples can come from two different patches or crops of the same image, or two other transformations of that image (for instance, two different rotations).
But this approach can be overly simplistic because it comes with a potential hazard. If there are two animals in the image, say a cat and a dog, the resulting pair may contain the patch depicting the dog and the one with the cat, which obviously should not be considered as containing the same semantic content. But a loss function based on the semantic identity of these patches would attempt to represent these two patches similarly in latent space, despite the fact the two have very different meanings.
Note: the proposed method also works for representation learning approaches that don't explicitly leverage the main assumption used in contrastive methods (that positive examples should lie close together in latent space and negative examples should lie farther apart in latent space). SwaV and ByOL (which only uses positive pairs) are notable examples of such approaches. We will mainly consider the proposed method for contrastive learning in this review.
The paper attempts to deal with “false” (having different semantic content) positive pairs by adaptively weighting them s.t. every positive pair's contribution to the loss function is proportional to its “semantic identity” (SI) score. In other words, for each pair of examples, the authors estimate the extent to which they contain a similar “semantic content”. The higher this score is, the greater the contribution of this pair to the loss function will be. This is similar in spirit to importance sampling, which is a statistical technique for sampling from complex probability distributions (by sampling from a simpler distribution and weighting samples by importance score).
Further details
Now we are ready to understand the mathematical principles behind the proposed approach. First, we recall the structure of the loss function used by representation learning methods. It is an average loss over many batches of positive example pairs. The loss for a batch is an average of loss function L values for the pairs comprising the batch. The question now is, what is the structure of L?
For a given positive pair of examples (sometimes negative ones, usually randomly selected) L determines "how closely these examples’ representations to the main assumption of the method". Now let’s elaborate on how L is computed for several well-known representation learning methods.
MoCO: L is the distance ratio between the representations of negative to the positive pairs.
SWaV: L is the distance between clusters of positive examples' representations.
ByOL: L is $L_2$ distance between representations of positive examples.
Next, we sample a set of positive (and sometimes negative ones) examples and evaluate L for each pair of this set.
To build positive pairs, we have to decide from which transformations (augmentations) distribution to sample. Most importantly, pairs of transformations producing images with identical, or at least similar semantic content, should have a high probability. Analogous pairs of transformations leading to images with different semantics should have a low probability. However, this distribution is unknown to us and, in addition, it can be dependent on an image. For example, two identical crops can have the same semantic content for one image (e.g. two cats) and completely different content (e.g. cat and grass) for another image.
To overcome this obstacle and sample from this unknown distribution, the authors use a method called importance sampling (IS). IS enables sampling from a complex, hard-to-sample distribution P using a different distribution Q, which is easier to sample. The weight of sample x is the ratio $\frac{P(x)}{Q(x)}$. Sample $x$ with a high value of $\frac{P(x)}{Q(x)}$ is given more weight, whereas the weight of low-ratio samples is low. In our case, $Q$ will be the known \(!!\) distribution from which we sample augmentations to construct positive pairs of samples.
But we have a problem here. We don't know how to compute $P(x)$ explicitly since we don't know the probability that a pair of augmentations will result in images with the same semantic content. Luckily we can estimate the ratio of $P(x)$ and $Q(x)$ directly and this is the most important point of the paper. The approximation is based on the fact that most augmentations maintain the same semantic content and there are only a few that don't. The main insight is that augmentations that do not maintain the same semantic content can be identified by analyzing their distance from the average representation of augmented images $z_{mean}$. $z_{mean}$ is an average representation of (denoted as M) augmented views of an image. Namely, if an image after applying augmentation A is too distant from $z_{mean}$ (in units of its standard deviation) then we can deduce that A does not retain the image semantic content.
Consequently, for a given sample, the weight w of augmentation A is defined as the distance of its representation after applying A from the mean $z_{mean}$ (in units of std computed over mini-batches):


The hyperparameter controls how much an augmentation weight will depend on the above-defined distance. The smaller is, the more sample weight will depend on this distance.
In a slightly more formal way: Let’s denote the "desirable" augmentation distribution by P. Since this distribution is unknown, we will sample from a different distribution Q, over the most commonly used augmentations (crop, rotation, etc). We leverage known distribution Q (containing commonly used augmentations) to sample from the desired distribution P using IS. That is, for a pair of examples $x_i$ and $x_j$ (which are the original image and its version after applying augmentation $A_j$ on it) we would like to calculate $\frac{P(Aj)}{Q(Aj)}$. Since we can not compute this ratio explicitly, as we do not know the desirable augmentation distribution P, we would like to estimate this ratio (denote it by $w_ij$). $w_ij$ is a weight of augmentation $A_j$ in the loss function - the more “content-preserving” $A_j$ is, the higher its weight is. As our belief in the content-preserving nature of $A_j$ lessens, so does its contribution to the loss function (the minimal weight value is 0). $w_ij$ can be estimated by a distance (very similar to Mahalanobis distance) of the image representation after applying augmentation A_j from the average representation $z_{mean}$ over M different augmentations of that image.
Results
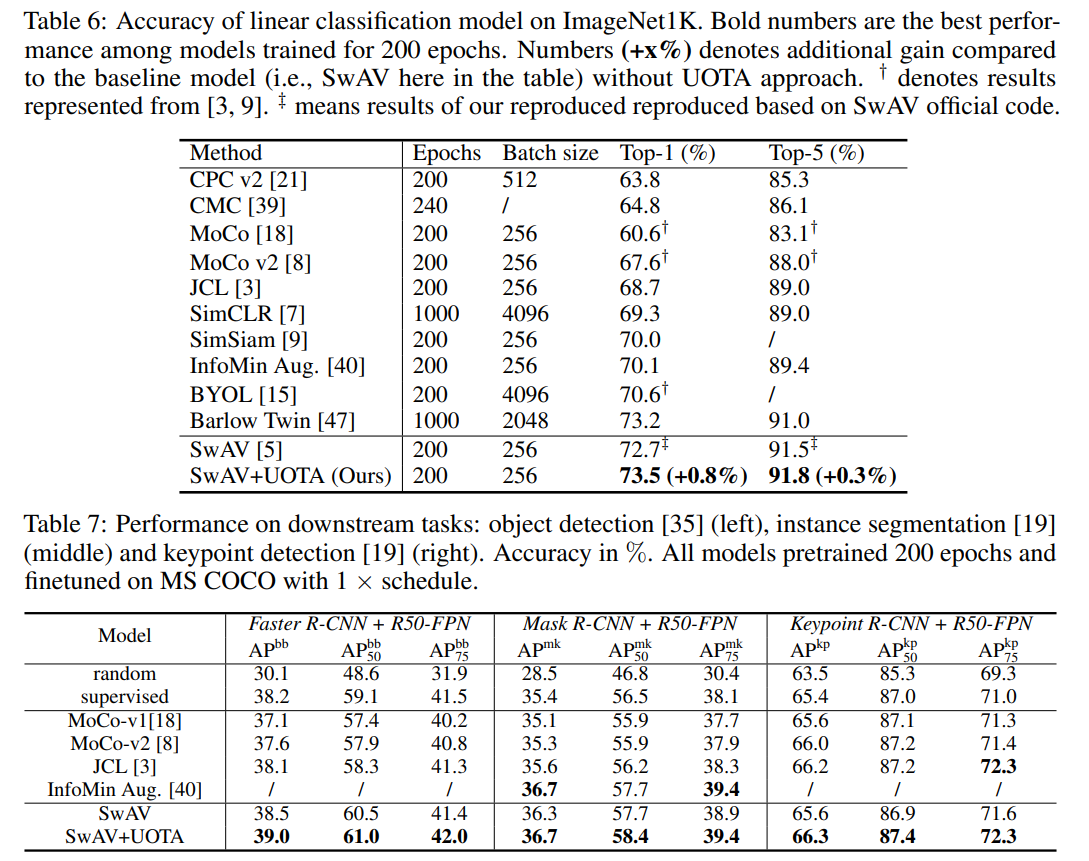
The paper compares many performance aspects of the proposed approach with many SOTA methods. The most important is a comparison of representations produced using the proposed technique with those of other unsupervised methods for object classification and object detection tasks. The proposed method achieves the best performance, but the performance margins over other methods are not too significant...

Post Scriptum
To sum up, this interesting paper proposes a method for addressing augmentation techniques that don’t preserve the semantic content of images for unsupervised representation learning tasks.
Thanks
We would like to thank Ido Ben-Yair for his assistance in translating this review and for pointing out important details.


